WorkQueue Model with POSIX Threads
少し前の記事で書きましたが、MNIST を MDS で処理する計算は、全て Python で書いたせいかパフォーマンスが悪く、N=10000 のデータにも関わらず N=200 程度で 6 分もかかってしまい、話になりませんでした。
MNIST with MDS in Python | すなのかたまり
https://msmania.wordpress.com/2015/12/13/mnist-with-mds-in-python/
しかし、ここまでやってようやく気づいてしまったのは、Field クラスは C++ で書いてしまったほうがよかったかもしれない、ということ。Sandy Bridge だから行列計算に AVX 命令を使えば高速化できそう。というか Python の SciPy は AVX 使ってくれないのかな。ノードにかかる運動ベクトルをラムダ式のリストにしてリスト内包表記で計算できるなんてエレガント・・という感じだったのに。
そこで、AVX 命令を使って演算するモジュールを C++ で書いて Boost.Python 経由で読み込むように書き換えてみました。(ばねの力を計算する部分で少しアルゴリズムも少し変えています。) 結果、期待していたよりもパフォーマンスが上がり、N=1000 でも 1 分弱、N=10000 の場合でも 1 時間程度で結果を得ることができました。
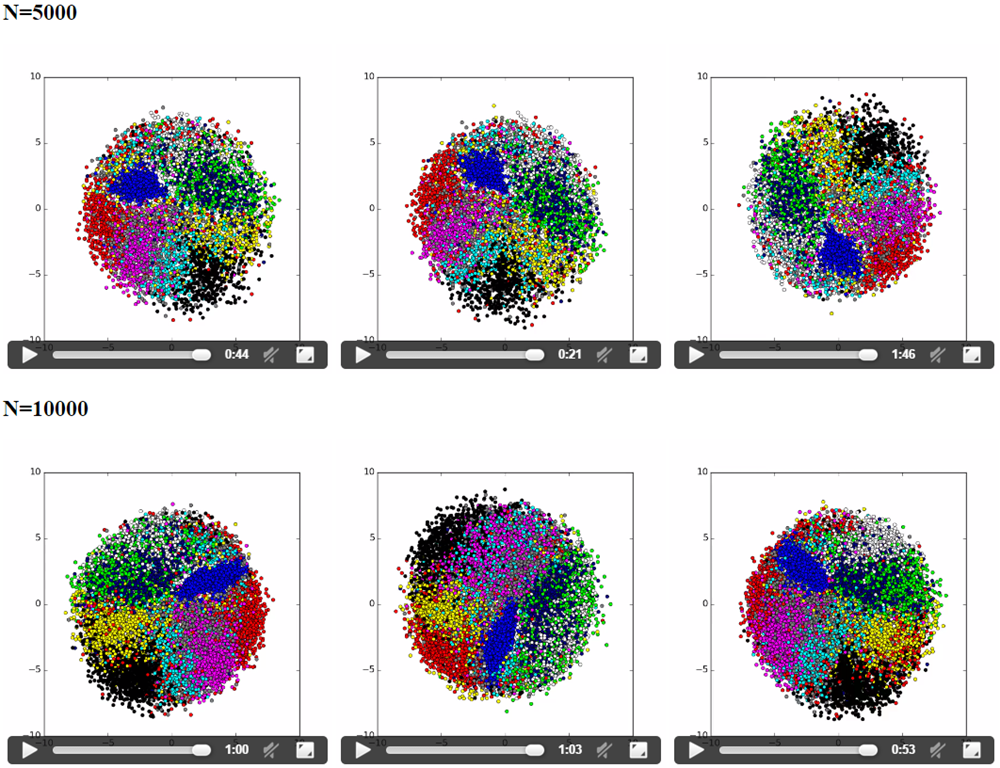
パラメーターをいろいろ変えて試しているので動きが統一されていませんが、結果はそれなりに統一されています。例えば、青色 (=1) のデータは、データ間の距離がかなり短いらしく収束が早いことがすぐに分かります。逆に、灰色 (= 8) や白色 (= 7) のデータは他の数字と混じっており、ユークリッド距離だけだと区別が難しそうです。緑 (= 4) と紺色 (= 9) は同じエリアを共有しがちですが、確かに数字の形を考えると、似ていると言えなくもありません。。
http://ubuntu-web.cloudapp.net/ems/cmodule.htm
結果の考察はさておいて、もう少し欲を出してみたくなりました。そこで試みたのは 2 点。
- ノードを動かす前に、各ノード間をばねで繋ぐ際のユークリッド距離の計算が遅い
-
オイラー法の計算の並列化
-
は未だ Python でやっており、N=10000 の場合だと、C(10000, 2) = 49,995,000 回も 784 次元座標のユークリッド距離を計算していることになるので、馬鹿にならない時間がかかります。入力データは変わらないので、予め全部の距離を計算してファイルに書き出しておくことにしました。おそらく、ファイルを読むだけの方が距離を計算するのよりは早いはずです。
- はそのままマルチスレッド化です。1 時間も 1 CPU だけが仕事をしているのは何かもったいないので、何とか並列化したいところ。アイディアとしては、扱っている 2 次元データを次元毎にスレッドを分けて計算したい、というものです。
結果から書くと、1 は成功、2 は失敗です。1. だけ実装して、N=10000 で 1 時間を切ることはできました。
計算の大部分を占めるのが、Field::Move で、最初にばねの力を足し合わせるためのループから Field::Spring::load を呼んでいます。次元毎に処理を分けるのは Move() 後半のループで、コード自体は簡単に書けましたが、パフォーマンスはほぼ同じか、少し悪くなりました。前半のばねの計算のところでは、ばね毎の計算を分けて各スレッドに割り振ってみましたが、こちらのパフォーマンスは最悪で、2 倍以上落ちました。
void Field::Spring::load() {
std::valarray<double> diff(_field->_dim);
int i, n = _field->_m.size();
double norm = .0;
for (i = 0 ; i < _field->_dim ; ++i) {
diff[i] = _field->_position[_n2 + i * n] - _field->_position[_n1 + i * n];
norm += diff[i] * diff[i];
}
norm = sqrt(norm);
for (i = 0 ; i < _field->_dim ; ++i) {
double f = _k * (1 - _l / norm) * diff[i];
_field->_accel[_n1 + n * i] += f / _field->_m[_n1];
_field->_accel[_n2 + n * i] += -f / _field->_m[_n2];
}
}
void Field::Move(double dt) {
int i, j, n = _m.size();
_accel = .0;
for (auto &f : _forces) {
if (f != nullptr) {
f->load(); <<<< この呼び出しを WorkItem にする
}
}
for (i = 0 ; i < _dim ; ++i) {
for (j = 0 ; j < n ; ++j) { <<<< このループを WorkItem にする
int idx = j + i * n;
_velocity[idx] += dt * _accel[idx];
_velocity[idx] -= _velocity[idx] * _friction[j] / _m[j];
_position[idx] += dt * _velocity[idx];
}
}
}
コードは dev-mt ブランチにまとめています。コミットの順番を間違えた上、マージのやり方も微妙でコミット履歴がぐちゃぐちゃ・・
msmania/ems at dev-mt · GitHub
https://github.com/msmania/ems/tree/dev-mt
Linux でマルチスレッドのプログラムをまともに書いたことがなかったので、最善か分かりませんが、Windows でよくある、WorkQueue/WorkItem モデル (正式名称が分からない) を POSIX Thread を使って一から書きました。もしかすると標準や Boost に既にいいのがありそうですが。
ヘッダーの workq.h
class WorkQueue {
public:
class Job {
public:
virtual ~Job() {}
virtual void Run() = 0;
};
private:
enum WorkItemType {
wiRun,
wiExit,
wiSync
};
class Event {
private:
pthread_mutex_t _lock;
pthread_cond_t _cond;
int _waitcount;
int _maxcount;
public:
Event(int maxcount);
virtual ~Event();
void Wait();
};
class WorkItem {
private:
WorkItemType _type;
void *_context;
public:
WorkItem(WorkItemType type, void *context);
virtual ~WorkItem();
virtual void Run();
};
int _numthreads;
std::vector<pthread_t> _threads;
Event _sync;
pthread_mutex_t _taskqlock;
std::queue<WorkItem*> _taskq;
static void *StartWorkerthread(void *p);
void *Workerthread(void *p);
public:
WorkQueue(int numthreads);
virtual ~WorkQueue();
int CreateThreads();
void JoinAll();
void AddTask(Job *job);
void Sync();
void Exit();
};
ソースの workq.cpp
#include <pthread.h>
#include <unistd.h>
#include <vector>
#include <queue>
#include "workq.h"
#ifdef _LOG
#include <stdio.h>
#define LOGINFO printf
#else
#pragma GCC diagnostic ignored "-Wunused-value"
#define LOGINFO
#endif
WorkQueue::Event::Event(int maxcount) : _waitcount(0), _maxcount(maxcount) {
pthread_mutex_init(&_lock, nullptr);
pthread_cond_init(&_cond, nullptr);
}
WorkQueue::Event::~Event() {
pthread_cond_destroy(&_cond);
pthread_mutex_destroy(&_lock);
}
// Test Command: for i in {1..1000}; do ./t; done
void WorkQueue::Event::Wait() {
LOGINFO("[%lx] start:wait\n", pthread_self());
pthread_mutex_lock(&_lock);
if (__sync_bool_compare_and_swap(&_waitcount, _maxcount, 0)) {
pthread_cond_broadcast(&_cond);
}
else {
__sync_fetch_and_add(&_waitcount, 1);
pthread_cond_wait(&_cond, &_lock);
}
pthread_mutex_unlock(&_lock);
}
WorkQueue::WorkItem::WorkItem(WorkItemType type, void *context)
: _type(type), _context(context) {}
WorkQueue::WorkItem::~WorkItem() {}
void WorkQueue::WorkItem::Run() {
switch (_type) {
case wiExit:
LOGINFO("[%lx] exiting\n", pthread_self());
pthread_exit(nullptr);
break;
case wiSync:
if (_context) {
((Event*)_context)->Wait();
}
break;
case wiRun:
((Job*)_context)->Run();
break;
default:
break;
}
}
void *WorkQueue::StartWorkerthread(void *p) {
void *ret = nullptr;
if (p) {
ret = ((WorkQueue*)p)->Workerthread(p);
}
return ret;
}
void *WorkQueue::Workerthread(void *p) {
while (true) {
WorkItem *task = nullptr;
pthread_mutex_lock(&_taskqlock);
if (!_taskq.empty()) {
task = _taskq.front();
_taskq.pop();
}
pthread_mutex_unlock(&_taskqlock);
if (task != nullptr) {
task->Run();
delete task;
}
else {
usleep(10000);
}
}
}
WorkQueue::WorkQueue(int numthreads) : _numthreads(numthreads), _sync(numthreads) {
pthread_mutex_init(&_taskqlock, nullptr);
_threads.reserve(numthreads);
}
WorkQueue::~WorkQueue() {
if (_threads.size() > 0) {
JoinAll();
}
pthread_mutex_destroy(&_taskqlock);
}
int WorkQueue::CreateThreads() {
int ret = 0;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
for (int i = 0; i<_numthreads ; ++i) {
pthread_t p = 0;
ret = pthread_create(&p, &attr, StartWorkerthread, this);
if (ret == 0) {
_threads.push_back(p);
}
else {
LOGINFO("pthread_create failed - %08x\n", ret);
break;
}
}
pthread_attr_destroy(&attr);
return ret;
}
void WorkQueue::JoinAll() {
for (auto &t : _threads) {
pthread_join(t, nullptr);
}
_threads.clear();
}
void WorkQueue::AddTask(Job *job) {
pthread_mutex_lock(&_taskqlock);
_taskq.push(new WorkItem(wiRun, job));
pthread_mutex_unlock(&_taskqlock);
}
void WorkQueue::Sync() {
pthread_mutex_lock(&_taskqlock);
for (int i = 0 ; i<_numthreads; ++i) {
_taskq.push(new WorkItem(wiSync, &_sync));
}
pthread_mutex_unlock(&_taskqlock);
_sync.Wait();
}
void WorkQueue::Exit() {
pthread_mutex_lock(&_taskqlock);
for (int i = 0 ; i<_numthreads; ++i) {
_taskq.push(new WorkItem(wiExit, nullptr));
}
pthread_mutex_unlock(&_taskqlock);
}
WorkQueue クラスがキューを持っていて、各ワーカー スレッドが放り込まれた WorkItem を逐次処理します。それに加えてある種の同期処理を付け加えました。今回の例で言えば、ばねの力を計算する WorkItem を全部投げ終わった後、速度や位置の計算をするためには、全てのばねの計算が完了していないといけません。つまり、WorkItem が全て処理されたかどうかを WorkQueue 側で判断できる機構が必要になります。
同期処理は、pthread に加えて条件変数 (condition varialbe) を使って実現しています。これは Windows のカーネル オブジェクトの一つであるイベントに似ています。WorkQueue::Sync() を呼ぶと、条件変数のシグナル待ちを引き起こす WorkItem をワーカー スレッドの数だけ投げ込んで、待機状態になったスレッドの数がワーカー スレッドと同じになるまで、Sync() を呼び出しているスレッドもを待機させておく、という動作を行ないます。
話を戻して、ばねの力の計算、すなわち Field::Spring::load() の並列化が失敗した原因は明白で、個々のワークアイテムが細かすぎたことと、ばねの力を加速度のベクトルに代入するときに排他ロックを獲得する必要があるからでしょう。これのせいで、WorkItem を出し入れしているコストがだいぶ高くついてしまいます。もし double をアトミックに加算する命令があれば排他ロックしなくてもいいのですが・・・。アルゴリズムでカバーするとすれば、ばねにつながっているノードがスレッドごとに重複しないように WorkItem を分ける方法がありますが、これだと、全部で C(10000, 2) = 49,995,000ある計算を C(5000, 2) 12,497,500 分は 2 スレッドで処理して残りの 25,000,000 は 1 スレッドで処理する、という感じになって、大して得しなそうなので断念しました。他にもっとうまい分け方を思いついたら試してみます。
速度と位置の計算は、単純に次元毎にスレッドを分けられるため排他ロックの必要はありませんが、やはり WorkItem が細かいので並列化のコストのほうが高くなってしまったのだと考えられます。3 次元プロットだったら使えるのかもしれませんが、まだそこまで手を出す段階じゃない・・。
こんなので土曜日が無駄になってしまった。もったいない。