Vectorized computation: R vs Python vs C++
前回のコードで、どうやら Python が遅いらしいことが分かったので、実際に C++ でモジュールを書き始める前に、どのぐらい遅いのかを調べてみることにしました。まずは軽く情報収集。
以下のページによると、Python は動的型付けなので、型チェックのせいで四則演算が遅くなるらしい。これは納得できる。さらに、NumPy は SIMD に対応していて、Cython を使うと速くなるとか。
Pythonを高速化するCythonを使ってみた - Kesin’s diary
http://kesin.hatenablog.com/entry/20120306/1331043675
その一方、R や Python の方が C より速くなる、というような不思議な結果を報告しているページもありました。この結論は原理的におかしいような気もしますが・・。
機械学習序曲(仮) > 数値計算の実行速度 - Python, C, Rの比較
http://hawaii.naist.jp/~kohei-h/my/python-numeric-comp.html
今回計測したいのは、2 次元ベクトルの四則演算 (オイラー法で、微小時間におけるベクトルの変化を計算するため)、及び、ばねの力を計算するときに使うノルムの計算です。というわけで、SSE や AVX といったベクトル演算用のユニット (= SIMD) をちゃんと使いたいところです。具体的には、こんな計算を計測することにしました。
V1 = V1 + d * V2
V1 と V2 は 2 次元ベクトルを横に P 個並べた行列、d はスカラーで、(0, 1) の範囲乱数を使います。この簡単な加算と乗算を N 回繰り返して速度を測ります。ノルムの演算は気が向いたら後で書き足します。
実行環境は以下の通り。
- OS: Ubuntu 15.10
- CPU: Intel(R) Core(TM) i5-2520M CPU @ 2.50GHz (Sandy Bridge)
- gcc (Ubuntu 5.2.1-22ubuntu2) 5.2.1 20151010
- Eigen 3.2.7
- Python 2.7.10
- R version 3.2.3 (2015-12-10) – “Wooden Christmas-Tree”
R と Python はそのまま、C++ では 6 つの処理系で比較します。C++ を使った場合の速度の違いで見ておきたいポイントは 2 つあり、一つは SIMD 演算で従来型の SSE を使うか Sandy Bridge から搭載された AVX 命令を使うかどうか、もう一つは、SSE/AVX 演算ユニットのスカラー演算を使うかベクトル演算を使うかという点です。前者は -mavx オプションで制御できます。後者は intrinsic を使って明示的に実装することもできますが、今回は gcc の自動ベクトル化機能を -ftree-vectorize オプションで有効にして利用します。ただし、最適化オプション -O3 を使うと、自動ベクトル化は勝手に行われます。よって、今回はベクトル化演算を行う前提で SSE と AVX でどれだけ違いが出るのかを見るのが趣旨です。というのも、SIMD は本来ベクトル演算向けのユニットなので、スカラー演算で使ってもあまり意味がないからです。
gcc のベクトル化に関しては ↓ が参考になります。
Auto-vectorization in GCC - GNU Project - Free Software Foundation (FSF)
https://gcc.gnu.org/projects/tree-ssa/vectorization.html
まとめるとこんな感じです。
| Language | Matrix datatype | Gcc option | SIMD |
| R | num(,) | N/A | ? |
| Python | numpy.ndarray | N/A | ? |
| C++ | std::vector | -O3 | vectorized, SSE |
| C++ | std:valarray | -O3 | vectorized, SSE |
| C++ | Eigen::MatrixXd | -O3 | vectorized, SSE |
| C++ | std::vector | -O3 -ftree-vectorize -mavx | vectorized, AVX |
| C++ | std::valarray | -O3 -ftree-vectorize -mavx | vectorized, AVX |
| C++ | Eigen::MatrixXd | -O3 -ftree-vectorize -mavx | vectorized, AVX |
で、書いたコードがこれです。いろいろ詰め込んだせいで無駄にファイルが多い。
https://github.com/msmania/ems/tree/perftest
主要なファイルについてはこんな感じ。
- perftest.R - R の計算ルーチン
- perftest.py - Python の計算ルーチン
- perftest.cpp - C++ の計算ルーチン
- main.cpp - 実行可能ファイル runc 用の main()
- shared.cpp - Python モジュール化のためのコード
- common.h / common.cpp - shared.cpp と main.cpp とで共有するコード
- draw.R - 結果を折れ線グラフで描く R のコード
コードを make すると、Python モジュールとしてインポートできる perftest.so と、スタンドアロンの実行可能ファイルである runc ができます。いずれのファイルにも、AVX を使った場合の関数と、使っていない場合の関数がそれぞれ avx、noavx という名前空間内に作られます。
Makefile の中で、perftest.cpp を別のレシピでコンパイルするようにしました。
override CFLAGS+=-Wall -fPIC -std=c++11 -O3 -g -Wno-deprecated-declarations
VFLAGS=-ftree-vectorize -ftree-vectorizer-verbose=6 -mavx -D_AVX
perftest.o: perftest.cpp
$(CC) $(INCLUDES) $(CFLAGS) -c $^
perftest_avx.o: perftest.cpp
$(CC) $(INCLUDES) $(CFLAGS) $(VFLAGS) -c $^ -o $@
-Wno-deprecated-declarations オプションは、Eigen のヘッダーをインクルードしたときに警告が出るので入れています。
では実測タイム。まずは Python から実行。引数の意味は、2 次元ベクトルを 10,000 個並べた行列を 1,000,000 回計算する、という意味です。
john@ubuntu1510:~/Documents/ems$ python perftest.py 10000 1000000
*** Python: numpy.ndarray ***
time = 26.096 (s)
*** R ***
[1] "*** matrix(n, 2) ***"
[1] time = 69.94 (s)
*** C++: no-vectorize no-avx ***
std::vector time = 11.398 (s)
std::valarray time = 11.371 (s)
Eigen::Matrix time = 10.547 (s)
*** C++: vectorize avx ***
std::vector time = 10.208 (s)
std::valarray time = 10.221 (s)
Eigen::Matrix time = 10.549 (s)
R 遅すぎ・・・。コンパイルされないからだろうか。Python も C++ と比べると 2 倍以上遅い。C++ については、avx と no-avx を比べると 10% ぐらい avx の方が速そう。もう少し試行回数を増やすため R と Python には退場してもらって、C++ だけ実行します。そんなときに runc を使います。
john@ubuntu1510:~/Documents/ems$ ./runc 10000 1000000 20 > result-O3-1000k
john@ubuntu1510:~/Documents/ems$ R
> source('draw.R')
> drawResult('result-O3-1000k')
runc の stdout への出力結果は R でそのまま読み込めるようにしているので、これをグラフ化します。レジェンドを入れていないので分かりにくいですが、青 = std::vector, 赤 = std::valarray, 紫 = Eigen、また、明るい色が AVX 有、暗い色が AVX 無になっています。
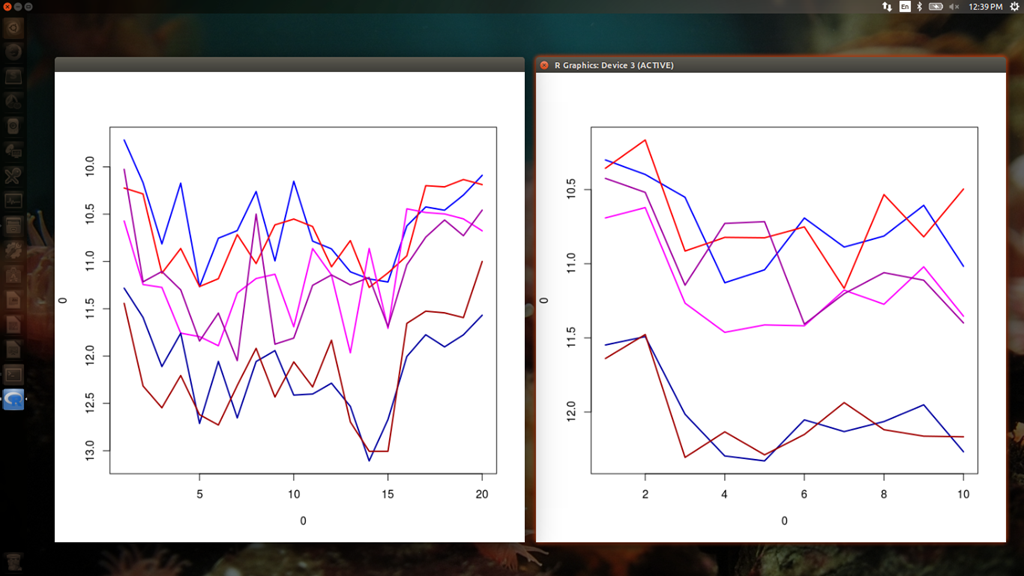
明らかに、AVX 無の vector と valarray は他より遅いです。AVX を使うと約 10% 速度が向上しています。逆に、Eigen は変化なしといってよさそうです。上位 4 つはほとんど差がありませんが、Eigen よりは AVX を使った vector/valarray の方が有利に見えます。
正直、AVX による速度向上が 10% 程度というのは期待外れでした。理想的には、レジスター サイズが xmm 系の 128bit から ymm 系の 256bit になることによって、速度は 2 倍ぐらいになって欲しいのです。本当に AVX が使われているかどうかを確認するため、生成されたアセンブリを見てみます。gdb を使って逆アセンブル結果をファイルに出力します。
john@ubuntu1510:~/Documents/ems$ gdb runc
(gdb) set height 0
(gdb) set logging file perftest.log
(gdb) i func Test
All functions matching regular expression "Test":
File perftest.cpp:
void avx::TestEigen(int, int);
void avx::TestValArray(int, int);
void avx::TestVector(int, int);
void noavx::TestEigen(int, int);
void noavx::TestValArray(int, int);
void noavx::TestVector(int, int);
(gdb) disas avx::TestEigen
(gdb) disas avx::TestValArray
(gdb) disas avx::TestVector
(gdb) disas noavx::TestEigen
(gdb) disas noavx::TestValArray
(gdb) disas noavx::TestVector
(gdb) set logging off
Done logging to perftest.log.
(gdb) quit
例えばavx::TestVectorをざっと見ると、以下の部分がベクトル演算をしているところです。pd というサフィックスが Packed Double を意味しています。
0x000000000040236b <+1035>: vmovddup %xmm0,%xmm9
0x000000000040236f <+1039>: xor %ecx,%ecx
0x0000000000402371 <+1041>: xor %r15d,%r15d
0x0000000000402374 <+1044>: vinsertf128 $0x1,%xmm9,%ymm9,%ymm9
0x000000000040237a <+1050>: vmovupd (%r10,%rcx,1),%xmm1
0x0000000000402380 <+1056>: add $0x1,%r15d
0x0000000000402384 <+1060>: vinsertf128 $0x1,0x10(%r10,%rcx,1),%ymm1,%ymm1
0x000000000040238c <+1068>: vmulpd %ymm9,%ymm1,%ymm1
0x0000000000402391 <+1073>: vaddpd (%r8,%rcx,1),%ymm1,%ymm1
0x0000000000402397 <+1079>: vmovapd %ymm1,(%r8,%rcx,1)
0x000000000040239d <+1085>: add $0x20,%rcx
0x00000000004023a1 <+1089>: cmp %r11d,%r15d
0x00000000004023a4 <+1092>: jb 0x40237a <avx::TestVector(int, int)+1050>
上記のコードの前半の vmovddup と vinsertf128 で、xmm0 に入っている 128bit の値 (double 2 つ分) を 2 つにコピーして ymm9 にセットします。おそらくこれは乱数の d です。次に、(%r10,%rcx,1) = r10 + (rcx * 1) のアドレスから 32 バイト (16 バイトずつvmovupd とvinsertf128 を使って) コピーして ymm1 にセットします。これは V2 でしょう。ここで AVX 命令を使って、V2 に d をかけて (%r8,%rcx,1) に加算しています。これが V1 になりそうです。このベクトル演算で、4 つの double を同時に処理していることになります。
avx::TestValArray にも同じ処理が見つかります。avx::TestEigen にも packed double を使っているコードは見つかりますが、ymm レジスタを使っていませんでした。これが、AVX の有無で Eigen の速度が変わらない理由として有力です。
0x0000000000402dcf <+511>: vmovddup %xmm1,%xmm1
0x0000000000402dd3 <+515>: xor %eax,%eax
0x0000000000402dd5 <+517>: nopl (%rax)
0x0000000000402dd8 <+520>: vmulpd (%r12,%rax,8),%xmm1,%xmm0
0x0000000000402dde <+526>: vaddpd (%rbx,%rax,8),%xmm0,%xmm0
0x0000000000402de3 <+531>: vmovaps %xmm0,(%rbx,%rax,8)
0x0000000000402de8 <+536>: add $0x2,%rax
0x0000000000402dec <+540>: cmp %rax,%rbp
0x0000000000402def <+543>: jg 0x402dd8 <avx::TestEigen(int, int)+520>
AVX 命令の利点の一つとして、従来の SSE 命令のオペランドの数が 2 つだったのに対し、AVX では 3 または 4 オペランドを使用できるようになっています。したがって、計算によっては mov の数を減らすことができるのですが、今回の例ではあまりそれは活きないのかもしれません。
ちなみに -O3 を -O2 に変更した場合、つまり SSE のスカラー演算と AVX のベクトル演算を比較すると、以下のように速度差がより顕著になります。この場合の Eigen のグラフを見るだけでも分かりますが、Eigen は最適化オプションが -O2 であってもベクトル化演算のコードを生成しています。
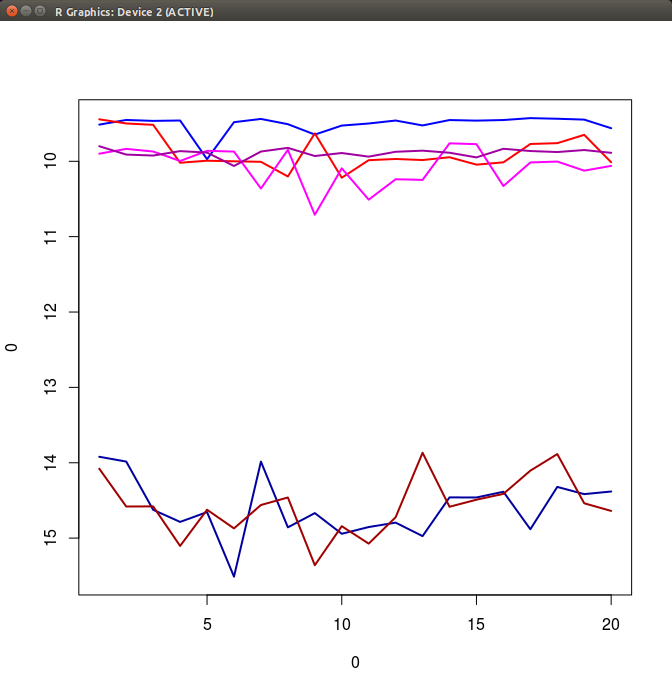
手元に Sandy Bridge 以前の CPU があったので、ベクトル化の有無で速度の違いを比べてみました。コンパイル時に gcc によるベクトル化に失敗したので、コンパイル オプションによる違いはなく、明らかに速度が Eigen > valarray > vector の順になっています。
CPU: AMD Athlon(tm) 64 X2 Dual Core Processor 3800+
というわけで結果からの考察。
- 特に工夫をしない場合、R と Python は遅い。
- SIMD を意識せずに書いた単純な C++ のループでも、ベクトル化 + AVX によって明白に速度向上が見込める。 というわけで何らかの方法 (既存のライブラリ、intrinsic、gcc のオプション) で必ずベクトル化はしておくべき。
- 明白な理由がない限り、 vector を使って自分でループを書くよりは、valarray の四則演算を使っておいた方が利点が多い。ベクトル化 + AVX を使った場合に両者の速度差はほとんどない上、valarray の方がコードが見やすい。 ただし、複雑な演算の時に、vector を使った方がループを工夫できる可能性はあるかも。
- Eigen は gcc の自動ベクトル化に頼らず自力でベクトル演算を使える。ただし (現バージョンの 3.2.7 では) AVX を有効にしても ymm レジスタを使わない。Sandy Bridge 以前の CPU では Eigen を使えば間違いない。Sandy Bridge 以降だと、valarray で間に合う演算であれば valarray を使う方がよい。
ただし上記は、SIMD を特に意識せずに C++ を書いた場合なので、intrinsic などを使えばもっと効率よくベクトル化の恩恵を受けられるかもしれません。もちろん、計算アルゴリズムやベクトルのサイズなどが大きく関係してくるので、一概にどれがベストと言い難いのですが、少なくとも、配列要素のアラインメントも特に指定しない単純なループでさえ、自動ベクトル化と AVX はそれなりに効果があるということが分かりました。この速度比較は、それだけで別のテーマになりますが今回はここまでにして、オイラー法は valarray でやってみようかな・・。
Skylake の Xeon モデルには 512bit レジスターを使う AVX3 ユニットが搭載されているらしい。これは使ってみたい。